- Trimmed sequence
길이가 다른 data - Omitted sequence
중간이 없는 data - Permuted sequence
밀리거나 순서가 바뀐 data
들로 인해서 sequential modeling이 어렵다.
이를 해결하고자 한 것이 Transformer이다.
Transformer
RNN은 재귀적으로 돌아갔는데, transformer은 attention을 사용해서 한 번에 모든 data를 찍어낼 수 있다.
transformer은 sequential한 data를 처리하고 encoding하는 방법이기 떄문에 다양한 문제에 적용될 수 있다.
기계어 번역, 이미지 분류, detection, 문장에 맞는 이미지 생성 등에 이용된다.

문장이 주어지면 다른 문장으로 바꾸는 sequence to sequence가 하고자 하는 것이다.
입력 sequence 와 출력 sequence의 길이, domain(다른 언어)은 다를 수 있다는 것이다.
입력 sequence를 재귀적이지 않고 한 번에 encode하고 decode는 auto regressive하게 한 단어씩 만들어낸다.
동일한 구조를 갖지만 네트워크 파라미터가 다르게 학습되는 encoder들과 decoder들이 쌓여있다.
Encoder
encoder에 단어가 한 개씩 들어가는 것이 아니라 여러 개가 한 번에 들어가게 된다.
data n개가 하나의 encoder 안에서 self-attention을 거쳐서 Feed Forward neural network를 거쳐 다시 n개로 출력된다. 그게 다시 2번째 layer encoder로 들어간다.

Feed Forward Neural network는 MLP의 연산과 다를 것이 없고 Self-Attention이 중요하다.
Self-attention에서는 각 단어마다 feature vector를 만든다. 그래서 n개의 단어로 이루어진 문장을 넣으면 n개의 feature vector가 만들어진다.
self attention에서는 해당 단어의 feature vector만 사용하는 것이 아니라 다른 단어의 feature vector도 함께 활용해서 output를 만든다. 이와 달리 Feed Forward NN에서는 다른 단어에 의존하지 않는다.
self-attention의 장점이 여기에서 나온다. 단어를 단어 그대로의 의미만 받아들이는 것이 아니라 문장속에서의 단어의 의미를 알 수 있게 한다. 다른 단어들과의 관계를 보고 학습한다.
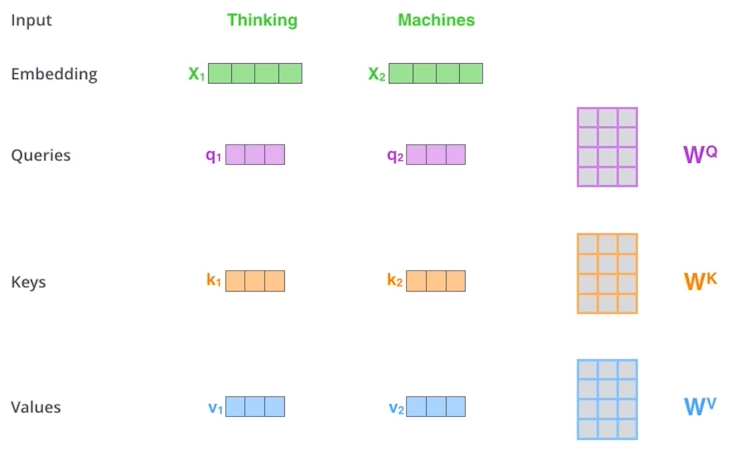
하나의 단어는 3가지의 vector를 만들어낸다. 그래서 3개의 neural network가 만들어진다. 바로 query, key, value vector들이다. 이 3개 vector로 embedding vector를 새로운 vector로 바꾼다.
| input | Thinking | Machines |
| score | $q_{1} \cdot k_{1}$ = 112 | $q_{1} \cdot k_{2}$ = 96 |
| normalize | 112/ $\sqrt{64}$ = 14 | 96/ $\sqrt{64}$ = 12 |
| softmax | 0.88 | 0.12 |
| softmax x Value vector | $0.88 \times V_{1}$ | $0.12 \times V_{2}$ |
| sum | $0.88 \times V_{1} +0.12 \times V_{2}=z_{1}$ |
일단 score vector를 만든다. encoding을 하고자 하는 단어의 query vector와 다른 모든 단어들(자기자신포함=encoding하고자하는 단어 포함)의 key vector를 내적한다. 그래서 query vector와 key vector의 차원은 같아야한다.
$$q_{1} \cdot k_{1}$$
그래서 해당 단어가 다른 단어들과 얼마나 유사도(관계)가 있는지 구한다. 얼마나 단어들과 interaction해야하는 지를 정하는 것이고 이게 attention이다.
구한 score를 normalize하는데, key vector의 dimension의 루트로 score를 나누어 준다. 그래서 score가 너무 커지지 않게 해준다. 모든 score들의 합이 1이 되도록 nomalize한 score에 softmax를 취한다.
그래서 직접적으로 사용할 값은 softmax취한 값과 value를 곱해서 더한 weight sum이 사용된다.
주의해야할 것은 이 모든게 오로지 Thinking이라는 단어에 대한 attention을 구한 것이다. machine 쪽에 적힌 것은 machine의 vector들을 활용했다는 의미이다.
이를 모든 단어에 적용할 때는 matrix로 보면 훨씬 쉽다.

X가 (2,4)인데 1행은 Thinking이라는 단어의 embedding, 2행은 machine의 enbedding이다.
각 weight를 만들기 위한 multi layer perceptron이 query, key, value만큼 필요하다.

위의 계산 과정을 이렇게 간단하게 표현할 수 있다.
encoding단어와 옆의 단어들에 따라서 출력이 달라지게 되기 때문에 MLP보다 flexible하고 많은 것을 표현할 수 있다. 하지만 그렇기 때문에 많은 계산이 필요하다.
예를들어 100개의 단어라면 transformer는 100*100 map의 입력을 처리해야한다. 하지만 RNN은 100개를 오래걸려도 순서대로 돌릴 수 있다. 그래서 이것이 transformer의 한계이다.
위의 과정까지가 하나의 attention head가 계산 된 것이다.
Multi-headed attention은 이 과정을 여러 번 해서 하나의 embedding에 대해서 여러개의 z(attention head)를 만든 것이다. 여러 개의 attention head들을 하나의 attention head size로 줄일 수 있는 weight를 곱해주면 마무리된다.
Positional encoding
입력에 특정값을 더해주는데 bias같은 것을 더해주는 것이다.
transformer 특성상 attention은 뽑아내지만 단어의 순서에 대한 정보는 들어있지 않다.
그래서 그 정보를 더해준다.
미리 정해져 있는 값들을 그 순서에 해당하는 값을 더해주는 것이다.
Decoder
decoder에서는 encoder에서 준 정보를 가지고 문장을 생성해낸다.
encoder에서 key와 value를 전달한다.
decoder에서 만들어보고자 하는 단어들에 대한 attention map만들려면 input에 해당하는 단어들의 key vector와 value vector가 필요하기 때문이다.
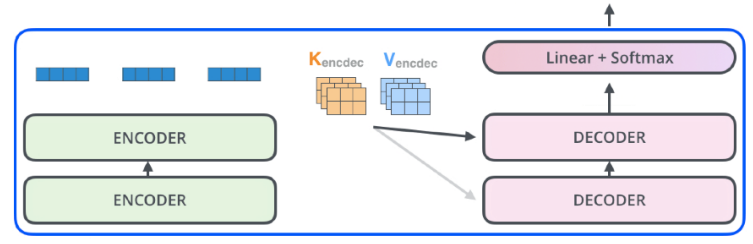
decoder에 들어가는 단어들의 query vector와 encoder에서 받은 key vector와 value vector를 가지고 최종 문장이 autoregressive하게 하나씩 만들어지게 된다.
미래에 나온 단어들을 미리 가지고 output을 만들면 안되니까 이전에 나온 단어들에만 dependent하도록 masking이라는 기법을 사용한다.
ViT : Vision Transformer
이미지 domain에서도 transformer가 사용되고 있다.
encoder만 활용해서 encoded vector를 바로 classifier에 집어넣는다.



