Regularization
generalization을 잘 되게 규제를 건다
학습을 방해하지만, test data에서도 성능이 잘 나오도록 방해한다.
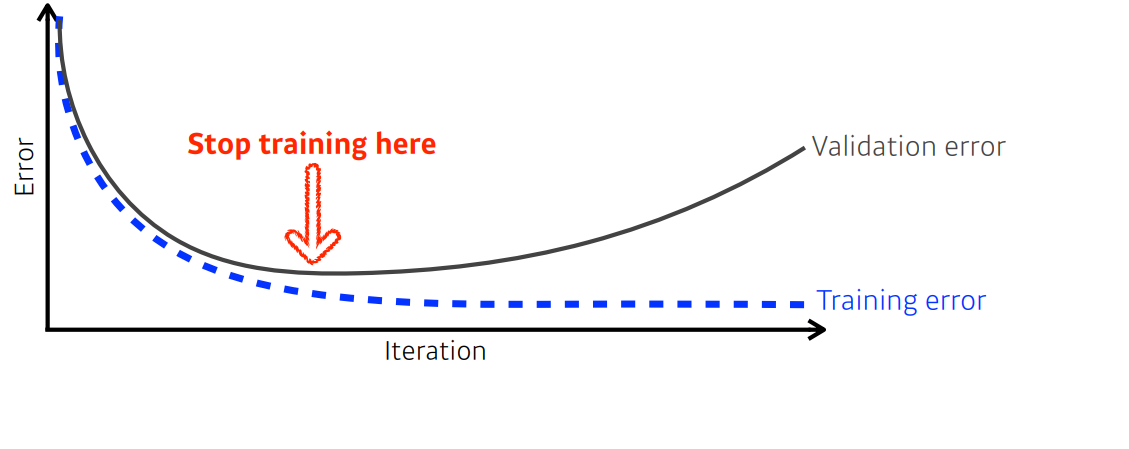
1. Early Stopping
validation error를 보고 loss가 줄어들다가 커지려고 할 때 학습을 멈추는 방법이다
2. Parameter norm penalty
파라미터가 너무 커지지 않게 하는 것
$$total cost=loss(\mathcal{D};W) + \frac{\alpha}{2}\parallel W\parallel^{2}_{2}$$
네트워크 안의 파라미터들을 모두 제곱하고 더한 수를 줄인다.
파라미터 크기를 줄이면 함수가 smooth해지고 generalization performance가 높을 것을 기대할 수 있다.
$\frac{\alpha}{2}\parallel W\parallel^{2}_{2}$ : Parameter Norm Panalty = weight decay
3. Data augmentation
데이터가 적으면 전통적인 ML방법론의 성능이 더 좋다.
하지만 데이터가 커지면 커질 수록 많은 데이터를 표현할 능력이 부족하기 때문에 Deep learning의 성능이 좋아진다.
그래서 가진 데이터를 사용해서 데이터 수를 늘리는 것이 data augmentation이다.
4. Noise robustness
입력 데이터에 noise를 집어넣고 weight에도 noise를 넣는 방법
5. Label smoothing
데이터 2개를 섞어준다.

두 class를 구분짓는 decision boundary를 부드럽게 만들어주는 효과가 있다.
6. Dropout
weight를 조금씩 0으로 바꾸는 것이다.
drop out ratio가 0.5면 뉴런의 반을 0으로 바꾼다.
각 뉴런이 좀 더 robust해지는 효과가 있다.
7. Batch normalization
layer의 statistics(파라미터들)를 정규화시킨다.
internal feature가 줄어들어서 학습이 잘 된다고 한다,,
'부스트캠프 AI Tech 3기 > 이론 : U-stage' 카테고리의 다른 글
| [Day14] DL Basic 5. Modern CNN (0) | 2022.02.09 |
|---|---|
| [Day14] DL Basic 4. Convolution은 무엇인가? (0) | 2022.02.09 |
| [Day13] DL Basic 3. Optimization -2 : Optimizers (0) | 2022.02.08 |
| [Day13] DL Basic 3. Optimization 최적화 - 1 (0) | 2022.02.08 |
| [Day13] DL Basic 2. 뉴럴 네트워크 - MLP (0) | 2022.02.07 |


