신경망 neural network
=perceptron
선형모델은 단순한 데이터에서는 가능하지만 복잡한 문제에서는 성능이 부족하다.
복잡한 문제에 대응하기 위해서 신경망을 사용한다.
신경망은 비선형모델이다. 선형모델이 숨겨져 있고 선형모델과 비선형함수의 결합으로 이루어져 있다.
비선형모델은 밑에 설명할 활성함수이다.
- $X$
데이터들로 이루어진 행렬 (n*d)
한 점으로 표현됨 - $W$
가중치 행렬(d*p)
데이터를 다른 데이터 공간으로 보내는 역할을 한다 - $b$
y절편에 해당하는 행벡터 1 (1*p) 개를 n개의 행렬만큼 늘려놓은 행렬(n*p)
각 행들이 전부 같은 값을 같게 된다. - $O$
출력 (n*p)
원래 데이터는 d차원이었는데, 출력을 하게 되면서 p차원으로 바뀌게 된다
$$\textbf{O = XW+b}$$

이렇게 x벡터 하나와 o벡터가 하나가 연결되는 모델이 p가 존재하게 된다.
각각 원소들을 연결시키는 화살표의 의미는 하나하나가 w한 개 라고 생각하면 된다.
※ bold체 소문자 Roman 정자: vector
bold체 대문자 Roman 정자 : 행렬
이탤릭 소문자 : vector의 원소
소프트맥스 함수 연산 softmax
모델의 출력을 확률로 변환해주는 함수
값을 이 함수에 대입하면 변환된다.
분류문제를 풀 때 선형모델을 softmax 함수에 대입하여 예측한다.
$$softmax(\textbf{o}) = softmax(\textbf{Wx+b})$$

각 출력벡터의 값에 지수함수를 씌운것을 더해준 것이 분모가 된다.
이렇게 선형모델로 출력된 값을 확률벡터로 바꾸어주어서 해석하고 분류할 수 있다.
원-핫 벡터 one-hot vector
학습중일 때는 확률로 학습을 해야하지만,
마지막에 분류를 할 때는 확률이 필요없이 정답을 하나 고르기만 하면 된다.
그래서 마지막에는 최댓값을 가진 주소만 1로 출력하는 one-hot을 사용한다.
활성함수 activation function
선형모델의 결과물을 원하는대로 해석할 수 있게 하는 함수
비선형함수를 모델링할 때 활성함수를 사용한다.
그래서 활성함수는 비선형함수이다.
$$ \sigma(\textbf{z}) = \sigma(\textbf{Wx+b}) =\textbf{H} $$
선형모델을 $\sigma()$라는 어떤 활성함수에 넣어서 그 결과가 출력이 되는 것이 아니라 hidden vector(잠재벡터)가 된다.
그래서 hidden vector $H$ 는 다음과 같다.
$$\textbf{H} = (\sigma(\textbf{z}_1), \dotsb, \sigma(\textbf{z}_n)) $$
이렇게 선형모델을 활성함수로 비선형모델로 변환시킬 수 있다.

softmax와 활성함수의 차이는 softmax는 모든 출력물($ \sigma(z_1) \dotsb \sigma(z_q)$)의 결과를 고려해야한다면
활성함수는 다른 출력들은 고려하지 않고 해당 동그라미($\sigma(z_q)$) 출력값에만 적용된다.
그래서 활성함수의 input은 하나의 실수 값이며 출력도 실수이다.
활성함수를 쓰지 않으면 딥러닝은 선형모형과 차이가 없다.
1. Sigmoid 시그모이드 함수
전통적으로 많이 사용했음

2. tanh 하이퍼볼릭 탄젠트 함수
전통적으로 많이 사용했음

3. ReLU 렐루 함수
오늘날 많이 사용
딥러닝 연산에서 많이 사용

다층 퍼셉트론 MLP : Multi Layer Perceptron
신경망이 여러층 합성된 함수

잠재벡터를 신경망이라고 하는데 위에서 잠재벡터는 선형모델의 결과를 활성함수를 함성한 결과였다.
그래서 신경망은 선형모델과 활성함수를 합성한 함수이다.
이 신경망(=퍼셉트론)이 여러층 쌓이게 되면 그것을 MLP 다층 퍼셉트론이라고 한다.
선형모델과 활성함수가 합성되는 것을 한 층으로 보아 layer를 센다
간단하게 W 행렬의 갯수라고 생각하면 된다.
위의 그림은 2층인데 이 위로 더 많이 쌓을 수 있다.
층을 여러 개 쌓으면 목적함수를 근사하는데 필요한 뉴런의 숫자가 빨리 줄어든다.
- 층이 얕다 ->뉴런의 숫자가 많이 필요하다 -> wide한 신경망
- 층이 깊다 -> 필요한 뉴런의 숫자가 상대적으로 빨리 줄어든다 ->좁은 신경망(잠재벡터들의 요소의 갯수가 줄어든다)
그래서 상대적으로 적은 파라미터로 복잡한 함수를 표현할 수 있기 때문에 사용한다.
하지만 복잡한 함수를 표현하면 할수록 최적화는 힘들어질 수 있다.
파라미터
- $\textbf{W}^{(L)}, \dotsb, \textbf{W}_{(1)}$
- $\textbf{b}^{(L)}, \dotsb, \textbf{b}_{(1)}$
총 L(layer의 갯수)개 의 가중치와 절편 벡터가 만들어지게 된다.
순전파 Forward Propagation
1->L까지의 순차적인 신경망 계산
학습이 아니라 연산이다
입력을 받아서 출력까지 보낼 때, 선형모델과 활성함수를 반복적으로 적용하는 연산이다
위의 다층 퍼셉트론 계산 과정이라고 생각하면 된다.
역전파 알고리즘 Backpropagation
경사하강법을 적용해서 가중치행렬을 학습시키는 과정
학습시키기 위해서는 각 층의 가중치행렬의 gradient vector를 계산해야한다.
경사하강법이 모든 $\textbf{W}^{(L)}, \dotsb, \textbf{W}_{(1)}$와 $\textbf{b}^{(L)}, \dotsb, \textbf{b}_{(1)}$의 각 요소에 적용된다
딥러닝의 경우는 층별로 계산을 해서 한 번에 gradient vector를 계산할 수 없고
역순으로 하되 순차적으로 계산해 나간다.
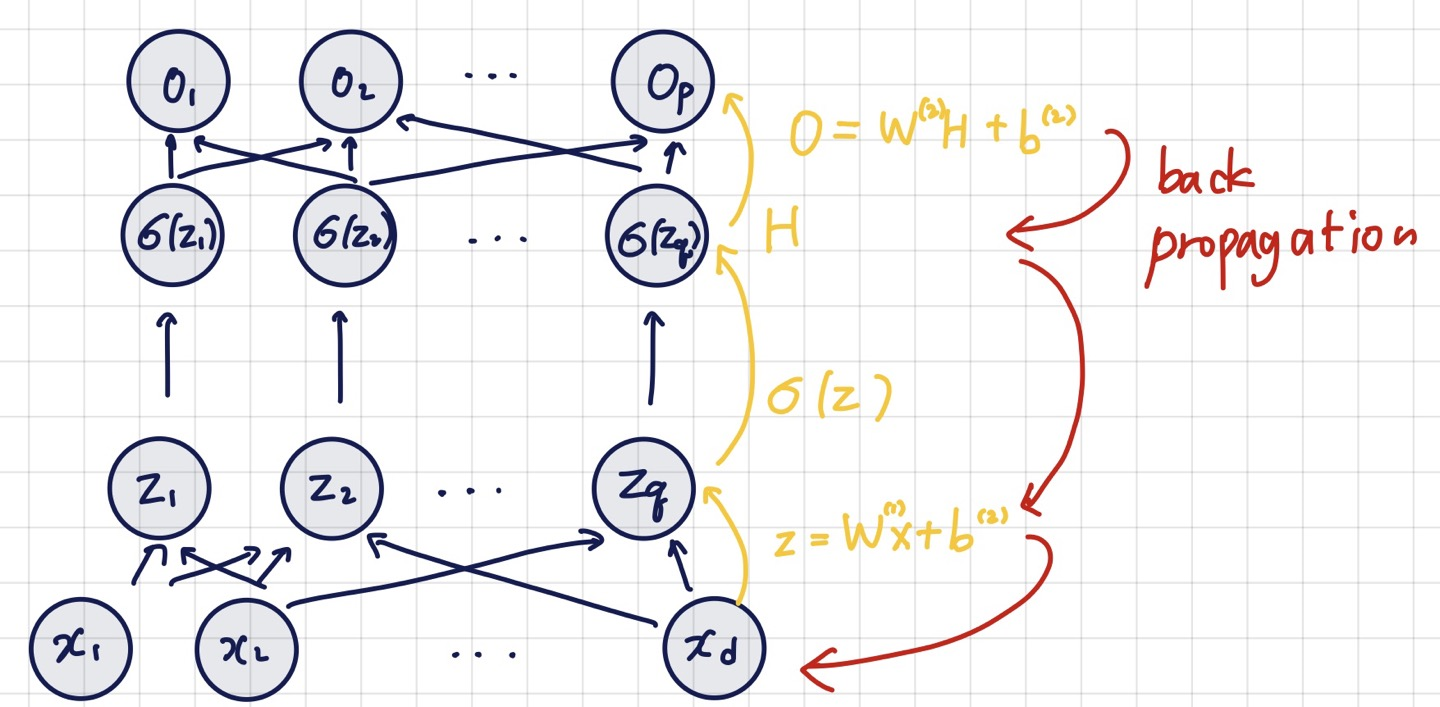
위의 gradient를 계산한 후에 밑으로 밑으로 내려가며 각 gradient를 계산하며 내려가며 update하는 방식이 backpropagation이다.
정확히는 각 층의 파라미터들의 gradient vector를 계산 한 후에 위층부터 아래까지 역순으로 gradient vector를 전달하면서 계산한다. 이때 연쇄법칙을 사용한다.
연쇄법칙 chain rule
합성함수를 미분하는 방식
딥러닝에서는 연쇄법칙기반 자동미분을 사용한다
$$\frac{\partial z}{\partial x} = \frac{\partial z}{\partial w}\frac{\partial w}{\partial x}$$
※각 뉴런에 해당하는 값=tensor 텐서 값
backpropagation은 각 노드의 텐서값을 기억하고 있어야 연산되기에 느리고 메모리 사용이 많이 된다.

예시로 2layer에서는 이렇게 계산이 될 것이다
(여기서 대분자 L은 Loss function 이다)
'부스트캠프 AI Tech 3기 > 이론 : U-stage' 카테고리의 다른 글
| [Day4] AI math 7. 통계학 맛보기 : 모수, 확률분포, 정규분포,최대가능도 추정법, MLE, 로그가능도, 확률분포 거리, 쿨백라이블러 발산 (0) | 2022.01.22 |
|---|---|
| [Day4] AI math 6. 확률론 맛보기 : 확률분포, 확률변수, 결합분포, 주변확률분포, 조건부 확률분포, 조건부 확률, 기대값, 몬테카를로 샘플링 (0) | 2022.01.21 |
| [DAY3] AI math 4. 경사하강법 -2 (0) | 2022.01.20 |
| [DAY3] AI math 3. 경사하강법 -1 (0) | 2022.01.20 |
| [DAY3] AI math 2. 행렬이 뭐예요? (전치, 행렬곱, 역행렬, 유사역행렬) (0) | 2022.01.19 |



