reshape
array의 shape의 크기를 변경하는데, element의 갯수는 동일하다.
import numpy as np
a=np.array([[1,2,3,4],[2,3,4,5]])
print(a.shape)
# (2,4)
print(a.reshape(8,))
# >>[1 2 3 4 2 3 4 5]
print(a.reshape(-1,2))
# [[1 2]
# [3 4]
# [2 3]
# [4 5]]
print(a.reshape(2,-1,2))
# [[[1 2]
# [3 4]]
#
# [[2 3]
# [4 5]]]어차피 정해진 element수는 계속해서 같기 때문에 나머지 하나를 -1 로 두면 알아서 남은 만큼으로 만들어준다.
이 코드에서는 a=a.reshape~~
이렇게 할당이 일어나지 않았기 때문에 a의 원본은 그대로 일 것이다.
flatten
다차원 array를 평평하게, 무엇이든 1차원으로 만든다.
reshape의 일종이다.
import numpy as np
a=np.array([[1,2,3,4],[2,3,4,5]])
a=a.flatten()
print(a)
>>[1 2 3 4 2 3 4 5]
print(a.shape)
>>(8,)
Indexing
list에서 [1][2]와 같이 썼던 것과 달리 [1,2]로 표기한다.
import numpy as np
a=np.array([[1,2,3,4],[6,7,8,9]])
print(a[0,2])
>> 3
a[0,0]=5
print(a)
# [[5 2 3 4]
# [6 7 8 9]]할당할 때도 마찬가지 이다.
Slicing
행과 열부분을 나눠서 slicing이 가능함 -> 부분집합 추출
import numpy as np
a=np.array([[1,2,3,4],[6,7,8,9]])
print(a[1,1:3])
>>[7 8]1이상 3미만이기 때문에 1,2만 나오게 된다.
a[:3,:4]처럼 비우게 되면 처음부터로 인식된다 -> a[0:3,0:4]
ex) a[:,3] 이면 전체 행을 다 포함하겠다는 의미이다.
import numpy as np
a=np.array([[1,2,3,4],
[6,7,8,9]])
print(a[1])
>>[6 7 8 9]
print(a[1:3])
>>[[6 7 8 9]]
print(a[:,::2])
# [[1 3]
# [6 8]]기법에 따라 dimension이 다르게 나온다.
starting point : end point : step이다.
creation function
arange
import numpy as np
a=np.arange(20).reshape(5,4)
print(a)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]
# [12 13 14 15]
# [16 17 18 19]]
print(np.arange(0,5,0.5).reshape(2,-1))
# [[0. 0.5 1. 1.5 2. ]
# [2.5 3. 3.5 4. 4.5]](시작, 끝, step)으로 하되, step이 소수단위일 수 있다.
ones, zeros, empty
import numpy as np
print(np.zeros(shape=(2,3), dtype=np.int8))
#[[0 0 0]
# [0 0 0]]
print(np.ones(shape=(3,2), dtype=np.int8))
#[[1 1]
# [1 1]
# [1 1]]
print(np.empty(shape=(3,), dtype=np.int8))
# [ 97 100 100]ones는 그 array를 1로, zeros는 0으로 만든다.
empty는 그 공간을 잡되, 값은 초기화 하지 않아(memory initialization) 그 전에 사용했던 값들이 그대로 나온다.
something_like
import numpy as np
a=np.zeros(shape=(5,), dtype=np.int8)
print(a)
#[0 0 0 0 0]
a=np.ones_like(a)
print(a)
#[1 1 1 1 1]해당 array의 크기만 똑같고 1로 채운다.
zeroes_like, empty_like도 있다.
identity
대각행렬이 1인 행렬 : 단위행렬 : i 행렬
import numpy as np
a=np.identity(n=2,dtype=np.int8)
print(a)
# [[1 0]
# [0 1]]정방행렬이기 때문에, shape 대신 n만 넣으면 된다.
eye
대각선이 1인 행렬, 대각선이 시작하는 값(k)을 정할 수 있다.
import numpy as np
a=np.eye(N=2,M=3,dtype=np.int8)
print(a)
# [[1 0 0]
# [0 1 0]]
a=np.eye(N=2,M=3, k=1,dtype=np.int8)
print(a)
# [[0 1 0]
# [0 0 1]]
diag
diagonal
생성되어있는 행렬에서 대각 행렬의 값만 추출한다.
import numpy as np
a=np.arange(12).reshape(3,4)
print(a)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
a=np.diag(a, k=1)
print(a)
# [ 1 6 11]k로 어느 열부터 시작할 지 정할 수 있다.
random sampling
데이터 분포에 따른 sampling으로 array를 생성한다
- uniform : 균등분포
균등한 분포로 뽑아준다.
uniform(시작, 끝, data size)
import numpy as np a=np.random.uniform(0,1,10) print(a) # [0.29653061 0.68464162 0.0065098 0.70473052 0.92269823 0.02500788 0.49976667 0.30327223 0.76092845 0.88860467] - normal : 정규분포
import numpy as np a=np.random.uniform(0,1,10) print(a) # [0.67312758 0.10332668 0.31482339 0.84585658 0.65531673 0.11195735 0.75686535 0.05800135 0.38200236 0.84505769]
Operation functions
axis
축 : operation function을 실행할 때 기준이 되는 dimension 축


새로생기는 축, 맨 마지막 차원이 axis 0이 된다.
sum
ndarray의 element의 합을 구해준다
import numpy as np
a=np.arange(1,11)
print(a.sum())
>>55
import numpy as np
a=np.arange(1,11).reshape(2,5)
print(a.sum(axis=0))
# [ 7 9 11 13 15]
print(a.sum(axis=1))
# [15 40]mean(평균), std(표준편차) 같은 함수도 있다.
axis도 적용할 수 있다.
concatenate
numpy array 끼리 붙이는 함수
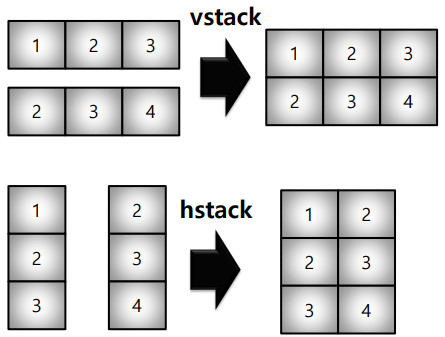
vstack과 hstack은 각각 vertical stack, horizontal stack이다.
import numpy as np
a=np.arange(1,4)
b=np.arange(4,7)
print(a,"----",b)
# [1 2 3] ---- [4 5 6]
print(np.concatenate((a,b), axis=0))
#[1 2 3 4 5 6]
Array operations
array간의 사칙연산 지원 : element-wise여서 같은 위치의 값끼리 연산된다.
import numpy as np
a=np.arange(1,4)
b=np.arange(4,7)
print(a,"----",b)
# [1 2 3] ---- [4 5 6]
print(a+b)
#[5 7 9]
print(a-b)
#[-3 -3 -3]
print(a*b)
#[ 4 10 18]dot product
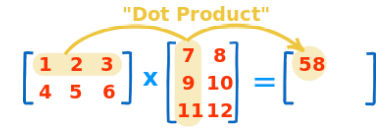
a.dot(b)
transpose
전치행렬
a.T
a.transpose()
broadcasting
shape이 다른 배열 간 연산
퍼지면서 연산 된다.
scalar와 matrix 연산이 이에 해당된다.
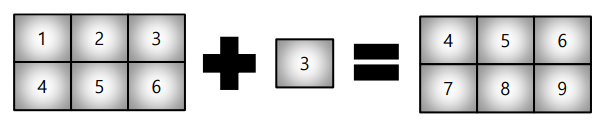

따로 함수가 있는 것은 아니고 연산하면 알아서 일어난다.
Numpy performance
코드의 퍼포먼스를 체크하는 함수 : %timeit
for loop < list comprehension < numpy
대용량 ======> numpy
Reference : 부스트캠프 AI Tech 3기 Pre-Course - Numpy


