Numpy : Numerical Python
파이썬의 고성능 과학 계산용 패키지
matrix, array 연산의 표준
특징
- List에 비해 빠르고, 효율적이다.
- 반복몬 없이 데이터 배열에 대한 처리를 지원
- 선형대수 관련 다양한 기능 제공
ndarray
numpy dimension array
import numpy as np
a=np.array([1,4,3], float)그냥 대부분 alias(별칭)을 np로 다들 둔다.
리스트랑 같은 기능이지만 메모리에 저장하는 방식이 다르다.
리스트는 static하게 [1]이 있다면 1이라는 숫자가 저장되어 있는 주소를 가리키는 포인터를 저장하는 방식이지만,
ndarray 는 메모리에 순서대로 저장되고 그 값도 따로 저장이 된다.
그래서 순서대로 저장되어 있기 때문에 연산이 빠르고 관리도 쉽다.
a=[1,2,3]
b=[3,2,1]
print(a[0] is b[2])
>>True
aa=np.array(a, np.int8)
bb=np.array(b, np.int8)
print(aa[0] is b[2])
>>False이 예시를 보면 명확하다. 리스트에서는 같은 수가 같은 주소를 가리키기 때문에 True가 나오지만,
ndarray는 만들 때 마다 새로운 연속적인 주소로 할당되기 때문에 False가 나온다.
중요한 특징은 하나의 데이터 type으로만 ndarray를 구성할 수 있다.
리스트는 ['3',3,3.0]의 작성이 가능하지만, ndarray로 저장하면 [3,3,3] 처럼 된다.(dtype을 int로 두었을 경우)
ndarray 선언시 dtype을 정하게 되는데, float64는 한 값당 64bit=8byte를 사용하겠다는 뜻이고, int32같은 것은 32bit를 사용하겠다는 것이다. np.float64와 같이 적어주면 좋다.
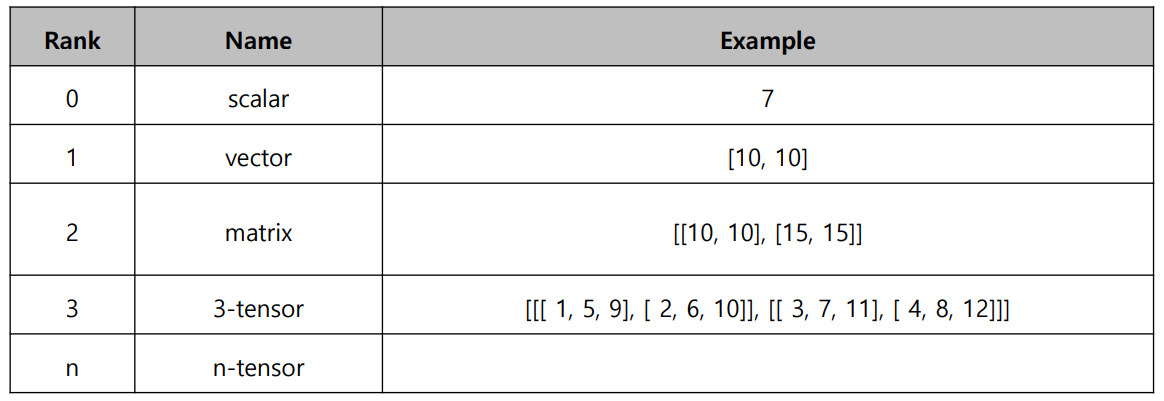
array의 rank에 따라 불리는 이름이 이렇게 다르다 (rank는 선형대수에서 배우는 개념)
shape
numpy array의 dimension 구성을 반환한다.
import numpy as np
a=np.array([1,2,3],np.int8)
print(a.shape)
>> (3,)
b=np.array([[1,2,3],[1,2,3]],np.int8)
print(b.shape)
>>(2,3)
c=np.array([[[1,2,3],[1,2,3]],[[1,2,3],[1,2,3]],[[1,2,3],[1,2,3]]],np.int8)
print(c.shape)
>>(3,2,3)튜플 형태의 output이 프린트 되는데, (column,) -> (row, column) -> (dimesion,row,column)
이렇게 된다. 규칙이 있는 것 같지는 않다.
dtype
ndarray의 single element가 가지는 data type
뒤의 숫자는 각 element가 차지하는 memory 크기 이다.

계산을 줄이려고 int8로 메모리를 최소화 할 때 말고는 거의 float64를 쓰게 된다.
dtype에 float64로 쓰면 에러가 나고, float나 np.float64로 쓰면 된다.
nbytes
ndarray object의 메모리 크키를 반환한다.
print(np.array([1,2,3], dtype=np.float32).nbytes)
>>12
print(np.array([1,2,3], dtype=np.float32).ndim)
>>1
print(np.array([1,2,3], dtype=np.float32).size)
>>332bit는 (1byte=8bits) 4bytes가 되고,
4bytes가 3개 있으니까 12bytes가 출력 될 것 이다.
ndim은 dimension의 갯수, [1,2,3]은 1차원이니까 1
size는 element의 갯수이다. 총 3개니까 3
Reference : 부스트캠프 AI Tech 3기 Pre-Course - Numpy


