Memory-based Collaborative Filtering
사용자나 아이템간의 similarity에 근거하고 있는 방법
이를 활용하여 rating prediction과 top-K ranking에 모두 적용될 수 있다.
Similarity Metrics
- Jaccarrard similarity
집합들간의 포함관계 - Cosine similarity
서로 다른 두 벡터 간의 각 거리 - Pearson similairity
cosine similarity와 유사하지만 평균을 뺀 잔차값을 다룬다
Memory-based CF for Rating Prediction
memory기반 CF를 rating prediction에 적용할 때는 휴리스틱 룰을 사용한다. 사용자가 아이템에 부여할 평점은 다른 유사한 사용자가 직접 부여하거나 아이템에 부여된 평점을 기반으로 새로운 평점에 대한 추정을 한다. 각 평점에 대한 weight를 similarity값으로 대체한다. 유사한 사용자일수록, 유사한 아이템일수록 더 높은 중요도를 가진다.
Item-to-Item Similarity
$r(u,i)=\frac{\sum_{j\in I_{u} \backslash \{i\}} R_{u,j} \cdot Sim(i,j)}{\sum_{j\in I_{u}\backslash \{i\}} Sim(i,j)}$
유저 u의 아이템 i에 대한 rating을 예측해보자. 아이템 i와 가장 유사한 아이템들을 j로 표현했다. i 와 j의 similarity가 높을수록 j에 대한 rating이 높게 가중된다.
User-to-User Similarity
$r(u,i)=\frac{\sum_{v\in U_{i} \backslash \{u\}} R_{v,i} \cdot Sim(u,v)}{\sum_{v\in U_{i}\backslash \{u\}} Sim(u,v)}$
마찬가지로 유저들간의 similarity에 기반하고 있다.
Model-based Collaborative Filtering
Model based CF중에서 대표적인 latent factor model에 대해서 알아보자. 이 때 사용자의 연령, 성별같은 명시적인 feature를 사용하지 않고도 R(interaction matrix)로 부터 잠재적인 표현을 학습할 수 있다.
Latent Factor Models
latent factor model은 사용자와 아이템의 저차원 표현을 학습하는 것으로 볼 수 있다.

행으로 된 것들이 유저이다. 위 행렬은 7명의 유저가 좋아하는 영화(1)와 싫어하는 영화(-1)에 대해서 평가했고 이 행렬 R를 $\gamma_U$와 $\gamma_I$로 분해할 수 있다.
$\gamma_U$의 각 행은 각 사용자가 histroy와 romance중에 어떤 것을 좋아하고 어떤 것을 싫어하는지와 같은 user preference를 의미한다. $\gamma_I$의 각 행은 각각의 영화들이 어떤 장르에 속하는지를 나타내는 Item property이다.
학습된 user latent factor ($\gamma_U$?)나 item latent factor를 같은 공간에 두면 잠재적인 의미를 내포하고 있는 것으로 나타낼 수 있다. 영화의 정보를 주지 않더라도 상호작용 이력만을 이용해서 아이템의 의미적인 특성이나 사용자의 잠재적인 선호도를 해석할 수 있다.
MF는 Latent Factor model의 대표적인 모델이다. MF는 추천시스템뿐만 아니라 dimensional reduction 테크닉이어서 다른 데이터 타입에도 적용이 가능하다.

이미지에 적용해서 얼굴의 특징 부위를 뽑아낼 수 있고 추출된 특징 부위에 대한 importance로 얼굴이 분해된다.

문서 집합에 적용하는 topic modeling도 MF를 통해 토픽을 추출할 수 있다. 토픽은 주제와 관련있는 단어의 집합이다.
M이라고 하는 Bag of words 행렬이 있을 때 토픽 A 행렬과 문서가 이 토픽을 얼마나 가지고 있는지 나타내는 행렬 W로 분해할 수 있다. Latent dirichlet Allocation도 사실 Matrix Factorization의 normalize된 버전이다.
Implicit Feedback for Recommendation
Implicit feedback은 explicit feedback과 달리 사용자의 선호에 대해 암시적인 정보만을 제공한다. 그러나 수집효율성이나 generalizability 때문에 오히려 성능에 효과적일 수 있다. 클릭행위, 구매, 기록 등에서 가져오기 때문에 양도 많고 이를 잘 분석함으로써 비즈니스 목표에 알맞는 형태로 달성할 수 있다. 즉, implicit feedack이 추천 태스크와 적합한 데이터일 수 있다.
야후에서 수행한 음악 관련 설문조사에서 랜덤하게 선택된 음악을 평가하게 했고, 원래 자발적으로 평가한 데이터도 있다. 원래 듣던 음악에 대한 평가는 uniform한데, 랜덤하게 선택된 음악은 평소에 듣지 않았던 음악이라서 선호하지 않는 경향이 컸다.
추천시스템에서는 관측된 데이터로부터 unseen data를 예측해야되는데 원래듣던 것 (관측된 데이터)에 대한 분포와 랜덤하게 선택된 음악(unseen)에 대한 분포 사이의 불일치가 컸다. 이렇게 explicit feedback에 존재하는 불일치 현상을 고려하지 않고 모델링을 하면 좋지 않은 결과가 나올 수 있다. 그래서 implicit feedback을 사용하는 것이 더 좋을 수 있다.
Explicit Feedback을 이용해서 RMSE를 최적화하는 것이 추천에 도움이 될까?
라는 질문에 '될 수도 있고 아닐 수도 있다'는 대답을 할 수 있다. RMSE로 추천되는 아이템들은 비슷한 별점의 비슷한 컨텐츠가 추천될 가능성이 높다. 물론 아이템이 사용자가 선호하는 것이기는 하지만 다양성이나 새로운 아이템의 발견이라는 측면에서는 사용자가 만족하지 못할 수 있다.
rating을 좋다(1) 싫다(0)로 간략하게 하는 추세이며, 5점 rating을 할 때 사용자가 한 번 더 고민을 하며 작성하지 않는 경향이 있다. 명확한 선호를 주고 사용자들에게 정보를 제공한다는 이점이 있다.
In-depth Discussion of Collaborative Filtering
Properties of Collaborative Filtering
CF는 행렬의 빈칸을 채우는 일종의 matrix completion문제로 볼 수 있다. 전통적인 matrix completion과 비교해서 훨씬 크고 sparse하다는 점에서 차이가 있다.
또한, 전통적인 classification이나 regression의 일반화 케이스로 볼 수 있다.
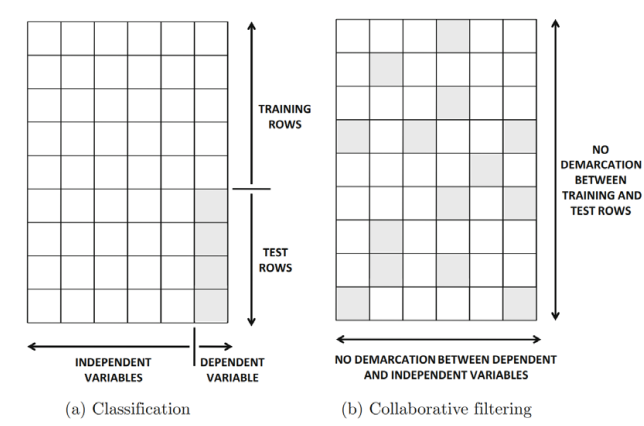
- label과 feature의 구분이 모호하다.
classification은 feature로 사용되는 independent variable과 답으로 사용되는 dependent variable의 구분이 명확하다. 하지만 CF는 빈칸의 분포가 랜덤해서 하나의 민칸을 채우기 위해서 매번 다른 feature들이 사용되고 다른 경우에는 답으로 사용되었는 label이 feature로 사용될 수 있다. - training과 testing의 구분이 행 구분이 아닌 entry단위로 이루어진다.
Cold Start
새로운 사용자나 아이템, 이력이 적은 경우 등에서 추천이 어려운 상황을 말한다.
CF는 새로운 사용자나 아이템이 들어오면 행이나 열로 들어온다. 그렇기 때문에 새로운 열이나 행은 기존에 사용하던 feature에 대응하지 않는다. training에서 볼 수 없었던 새로운 feature가 테스트 상황에 존재하게 되는 것이다.
그래서 content-based 방법이 cold start에 조금 더 robust하다. 아이템의 이미지, 텍스트와 같은 컨텐츠를 기반해서 사용자-아이템 interaction에 비해서 좀 더 universal(보편)해서 그렇다.
"User-free" Model-based Approaches
모델에 기반을 두며 similarity개념(memory-based)을 활용한다. compatibility function을 정의함에 있어서 user term을 제거한다. $f(u,i) = \gamma_u\cdot\gamma_i$
$\gamma_u$를 사용하지 않을 때 장점
- 새로운 사용자에 대한 inference가 가능하다
$\gamma_u$를 사용하는 모델들은 새로운 사용자가 등장할 때마다 재학습해야 했었다. 재학습은 deployment를 고려하면 큰 단점이다. - 이력이 거의 없는 사용자에 대한 대응이 가능하다.
MF 모델은 사용자 정보가 없으면 $\gamma_u$가 제대로 학습되지 않아서 성능이 좋지 않다. - sequential 시나리오에 대해 대응이 가능하다.

이력을 item vector형태로 받아서 입력으로 활용한다.
$$f(u,i) = R_u\cdot W_i=\displaystyle\sum_{j\in I_u} R_{u,i}W_{i,j}$$
Linear regression 처럼 사용자의 다른 아이템 사용 이력$R_u$과 weight(학습해야 할 학습 파라미터 : $W_{i,j}$)를 곱해준다. 이 형태는 item-to-item memory based CF의 식
$$r(u,i)=\frac{\sum_{j\in I_{u} \backslash \{i\}} R_{u,j} \cdot Sim(i,j)}{\sum_{j\in I_{u}\backslash \{i\}} Sim(i,j)}$$
에서 similarity $Sim(i,j)$를 사용하는 대신 W_{i,j}가 사용되는 것으로 보면 된다.
SLIM : Sparse Linear Methods
Memory-based + Model-based
주로 top-N recommender에 사용된다. Linear regression objective에 더불어서 regularization와 constraint도 추가되어 constrained linear regression형태로 표현된다.
$$\arg\min_{W} \parallel R -RW^T\parallel^2_2 + \lambda\Omega_2(W) + \lambda'\Omega_1(W)$$
$$s.t. W_{i,j}\geq0; W_{i,i}=0$$
L1,L2 regularization을 적용해서 elastic regularization을 포함한다.
$W_{i,j}\geq0$ : similarity관점에서 해석을 쉽게 하기 위해서 weight를 0이상으로 한다.
$W_{i,i}=0$ : 아이템 i에 대한 예측을 수행함에 있어 자기자신의 정보를 이용해 trivial solution에 도달하는 것을 막기위해서 대각원소를 0으로 제약한다.
새로운 사용자나 상호작용이 추가되더라도 학습된 W가 있다면 R을 바꾸어 재학습 없이 추천결과를 제공할 수 있다. 사용자가 첫 상호작용을 한 이후부터 할 수 있다. MF계열에 비해서 long-tail term(유명하지 않은 아이템)에 대해서 performance가 뛰어나다.
FISM : Factored Item Similarity Model
Latent Factor Model($\gamma_u\cdot\gamma_i$)에서 $\gamma_u$를 사용자의 기존 이력에 기반한 aggregated item representation으로 대체했다.
$$f(u,i) = \alpha+\beta_u+\beta_i +\frac{1}{|I_u\backslash \{i\} |} \displaystyle\sum_{j\in I_u\backslash \{i\}}\gamma_j' \cdot \gamma_i$$
aggregated item representation을 계산하기 위해서는 현재 사용자가 사용한 아이템에서 해당 아이템 i를 제외하고 $I_u\backslash \{i\}$ 나머지 아이템의 representation의 평균을 취한다. 이 사용자를 나타내기 위해서 해당 사용자가 사용했던 다른 아이템을 사용하는 것이다.
데이터셋이 더욱 sparse할 수록 baseline에 비해서 성능 향상이 크다. user free model의 특징이기도 하다.
기타 user-free 모델
- U-AutoRec
- Item2Vec
- Sequential Recommendation Models
'부스트캠프 AI Tech 3기 > 프로젝트 : P-stage' 카테고리의 다른 글
| [Day62] DKT 1. DKT 이해 및 DKT Trend 소개 (0) | 2022.04.20 |
|---|---|
| [Day41] Movie Rec 4. Collaborative Filtering (2) (0) | 2022.03.22 |
| [Day40] Movie Rec 2. Research Directions and Resources (0) | 2022.03.21 |
| [Day40] Movie Rec 1. 추천 시스템 개요 및 대회 소개 (0) | 2022.03.21 |
| [Day22] 이미지분류 3. Dataset (0) | 2022.02.27 |



