Interesting Reseasrch Directions
SOTA RecSys 연구의 근간이 되는 논문들을 살펴보자
Matrix Factorization
사용자와 아이템의 저차원 표현을 학습한다. 명시적인 아이템이나 사용자의 feature를 사용하지 않고도 잠재적인 표현을 학습하기 때문에 latent factor model이라고 한다.

R이라는 상호작용 matrix를 $\gamma_U$와 $\gamma_I$로 분해했을 때 $\gamma_U$의 한 행은 유저의 preference를 의미하고 $\gamma_I$의 한 열은 아이템의 특징을 의미한다. $\gamma_U$와 $\gamma_I$를 같은 공간상에 도식화 했을 때, 각 축이 의미하는 것은 장르, 나이 등 하나의 의미를 갖는 축이 된다.
explicit data을 사용할 때는 rating을 예측하고 RMSE로 평가하며, implicit data에는 ranking을 수행하고 regression이나 classification 또는 regression의 문제로 풀게 된다. explicit data를 수집하기 어렵기 때문에 Top-k ranking 관련 연구가 많이 진행되고 있다. 대용량의 implicit 데이터를 이용해서 추천시스템에 활용하고 있다.
행렬의 각 원소에 서로 다른 confidence값을 부여하는 instance re-weighting scheme이 활용된다. $r_{ui}$가 사용자 u가 영상 i를 클릭한 횟수라고 했을 때 confidence weight $c_{ui}$ 를 계산하기 위해서 $r_{ui}$를 활용한다. $p_{ui}$는 $r_{ui}$가 존재하면 1 아니면 0인 값이다.
Bayesian Personalized Ranking
사용자의 선호도를 두 아이템 간의 pairwise-ranking문제로 formulation함으로써 사용자 u를 위한 personalized ranking function을 추정한다. 기존의 explicit feedback을 다루던 한계를 극복하고자 하였다. 기존에는 missing value=0 으로 처리해서 선호할만한 아이템이 0에 섞이게 되는 문제가 있었다. 한 번도 보지 않은 item에도 negative scoring하는 케이스가 존재했다. BPR에서는 두 scoring사이의 크기를 비교하는 방식을 채택했다.
positive instance (+) : 높은 점수
non-positive snstance (?) : 낮은 점수
- $i>_{u}j$
personalized ranking function
유저 u 가 아이템 i를 j에 비해서 더 좋아한다. - $\hat{x}_{uij}$
personalized ranking function을 추정하기 위한 predictor
$\hat{x}_{uij}>0$이면 사용자가 i를 좀 더 선호한다는 의미, $\hat{x}_{uij}\leq0$이면 j를 좀 더 선호한다는 의미가 된다.
개인의 pairwise preference에 대한 확률을 구하게 된다.
$$p(i>_u j)=\sigma(\widehat{x_{uij}}(\Theta))$$
즉, 사용자 u가 아이템 i를 j에 비해 더 좋아할 확률을 분류하는 classification 문제를 풀게 된다.
$\hat{x}_{uij}$가 어떤 형태를 따르는지에 따라서 BPR의 objective function의 형태가 결정된다. 가장 간단하게 정의하면 $\hat{x}_{uij}=\hat{x}_{ui}-\hat{x}_{uj}$ 와 같이 (사용자 u의 아이템 i에 대한 선호도)-(사용자 u의 아이템 j에 대한 선호도) 로 i를 j에 비해 얼마나 더 좋아하는지로 정의할 수 있다.
각 compatibility function $\hat{x}_{ui}$과 $\hat{x}_{uj}$는 latent factor model의 결과값으로 정의할 수 있다. 즉, $\hat{x}_{uij}=\hat{x}_{ui}-\hat{x}_{uj}= \gamma_u\dot\gamma_i-\gamma_u\dot\gamma_j$로 정의할 수 있다. 이렇게 정의하면 MF와 BPR의 차이가 명확해진다.
| Matrix Factorization | Bayesian Personalized Ranking |
| 하나의 아이템에 대한 pointwise한 estimation | 두 아이템을 서로 비교하는 pairwise한 optimization |
| explicit feedback을 사용하며 MSE를 직접적으로 optimize하는 regression을 취했다 | 분류 문제 |
BPR의 objective function을 최적화하는 것이 AUC를 optimize하는 것과 동일하다고 논문에서는 주장한다.
AOC
classifier가 임의의 positive, negative sample이 주어졌을 때 negative sample보다 positive sample을 더 높은 순위로 평가할 확률
BPR에 적용하면 어떤 사용자가 임의의 아이템 i와 j가 주어졌을 때 positive item i를 j에 비해서 조금 더 높은 순위로 평가할 확률이라고 볼 수 있다. 그러면서 AOC에서의 heavyside function 을 미분 가능한 log sigmoid로 대체했다.
Factorizing Personalized Markov Chains : FPMC
MF와 Markov chain의 장점을 결합한 모델
사용자와 아이템 간의 관계뿐만 아니라 아이템과 바로 이전 아이템 간의 관계도 모델링한다.
Markov property
다음 step의 상태를 예측함에 있어서 바로 전 상태에만 영향을 받는 상황
FPMC에서는 이 Markov property를 따르는 Markov chain을 개인화된 형태로 도입한다. 사용자마다 현재 스텝과 이전 스텝의 전이 확률이 다르기 때문에 이런 것을 반영한다.
같은 이력에 대해서 markov기반 추천과 MF기반 추천이 어떻게 다른지 알아보자.
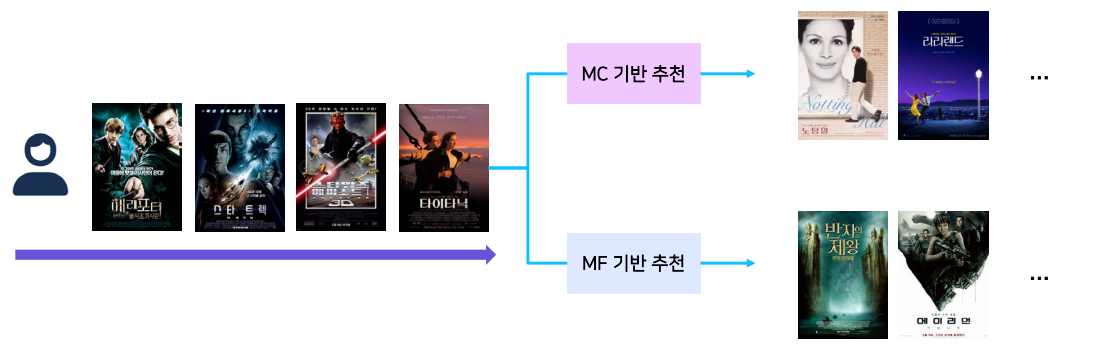
Markov Chain 기반 추천은 바로 전 스텝에서 본 타이타닉에만 영향을 받기 때문에 노팅힐 같은 원래 취향과 조금 거리가 먼 영화를 추천해줄 수 있다. MF 기반 추천은 전체적인 이력을 함께 고려하기 때문에 취향에 알맞은 추천 결과가 제공될 수 있다.
$$f(i|u,j)$$
j를 이전 스텝에서 소비된 item이라고 하자
그러면 FPMC는 f함수를 fitting하는 문제가 된다. 위의 식은 사용자 u에 대해서 아이템 i를 좋아할 확률을 나타내는 값이다. 이 때 j가 주어지기 때문에 함께 고려한다. 지금까지 배웠던 대부분의 compatibility function은 $f(u,i)$로 2차원의 아이템과 유저간의 관계만을 다루고 있었다. 여기에 j가 추가되어 matrix가 아닌 tensor로 표현되게 된다. tensor의 원소에는 transition probability를 저장하고 있다.
tensor를 어떻게 분해하는 지가 FPCM의 핵심적인 아이디어이다.

위와 같이 3가지의 합으로 구분될 수 있다. 결과적으로 $f(i|u,j)$를 BPR-like framework에 도입하므로써 최적화하게 된다. $f(i|u,j)$를 그대로 두고 negative item $f(i^{-}|u,j)$와의 차이를 personalized 형태로 도입하게 된다. 식이 정리되면서 3번째 항인 사용자와 이전 아이템의 compatibility는 서로 지워지면서 앞의 두 가지(사용자와 다음 아이템의 compatibility, 이전 아이템과 다음 아이템의 compatibility)가 실제로 쓰이게 된다.
성능은 FPMC > FMC(Factorized Markov Chain) >MF >MC 순으로 뛰어나다.
| User factor | Sequential Factor | |
| FPMC | O | O |
| FMC | X | O |
| MF | O | X |
Personalized Ranking Metric Embedding : PRME
compatibility function으로써 단순한 inner product ($\gamma_u\dot\gamma_i$)대신 euclidean distance metric( d($\gamma_{u} \dot \gamma_i$) )을 사용한다.
사용자와 다음 item간의 euclidean distance, 다음 item과 이전 item간의 euclidean distance를 함께 고려한다.

왼쪽은 inner product로 추천, 오른쪽은 euclidean distance를 locality를 고려한 추천이다. 추천 범위를 색을 칠해서 보여주는데 왼쪽은 각도간의 거리가 좁을 수록 score가 높고, 왼쪽은 정말 거리적으로 가까운 아이템이 높은 score를 받는다.
이러한 형태의 compatibility를 사용하면 locality를 고려해서 인접한 것이나 장소를 추천하는 POI와 음악 도메인에서 효과적이다.
Evaluating Recommender Systems
Rating Prediction
실수로 이루어진 explicit feedback을 에측하는 task에 사용한다. RMSE와 같은 Objective function을 도입해 바로 최적화 한다.
Top-K Ranking
0과1의 binary로 클릭이나 구매와 같은 implicit feedback을 예측한다. Regression이나 classification으로 모두 풀 수 있다. Recall@K, NDCG@K와 같은 metric으로 평가한다.
사용자의 compatibility score을 아이템에 대해 높은 순으로 ranking하여 추천 결과를 생성한다. 상위 K개의 추천 중 몇 개나 유효한 지를 평가한다.
'부스트캠프 AI Tech 3기 > 프로젝트 : P-stage' 카테고리의 다른 글
| [Day41] Movie Rec 4. Collaborative Filtering (2) (0) | 2022.03.22 |
|---|---|
| [Day40] Movie Rec 3. Collaborative Filtering (1) (0) | 2022.03.22 |
| [Day40] Movie Rec 1. 추천 시스템 개요 및 대회 소개 (0) | 2022.03.21 |
| [Day22] 이미지분류 3. Dataset (0) | 2022.02.27 |
| [Day22] 이미지분류 2. Image Classification & EDA (0) | 2022.02.27 |



