RNN Families
RNN : Recurrent Neural Network
시퀀스 데이터의 처리와 이해에 좋은 성능을 보이는 신경망 구조
현재 상태가 다음 상태에 영향을 미치도록 루프구조로 고안되어 있다.

sequencial한 input이 들어오면 각 셀이 계산되어서 다음으로 넘어간다.
LSTM : Long-Short Term Memory
RNN계열의 대표적인 모델
시퀀스가 길어질 수록 학습능력이 떨어지는 RNN의 한계를 cell state라는 구조로 극복했다.
- forget gate
전 cell에서 전달된 기억을 얼마나 살릴 것인지 - input gate
입력된 입력변수를 얼마나 사용할 것인지 - output gate
얼마나 출력할 것인지
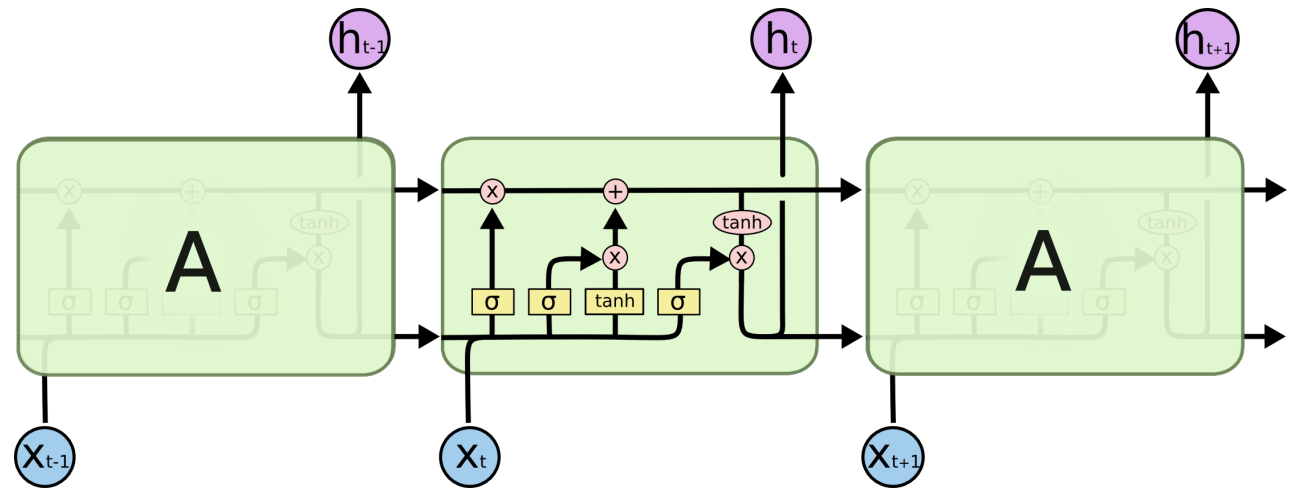
cell state는 계속 해서 다음 cell 로 넘어가기 때문에 장기 기억을 전달하는 역할을 한다.
GRU : Gated Recurrent Unit
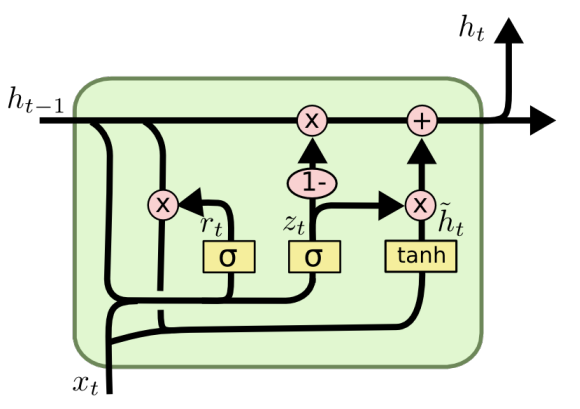
LSTM과 달리 출력 게이트가 없어서 파라미터와 연산량이 적다.
더 가볍지만 성능차이는 LSTM과 비교해서 크지 않다.
GRU4Rec
Session based Recommender System
추천시스템에 sequence를 더한 문제
고객의 선호가 시간에 따라서, 무엇을 소비해 왔느냐에 따라서 달라지기 때문에 고객이 지금 무엇을 좋아할지를 추천해야한다.
Session : 유저가 서비스를 이용하는 동안의 행동
하나의 세션안에서 여러 아이템을 소비했을 때 그 다음에 무슨 아이템을 소비할지 예측한다.
GRU4Rec은 GRU layer를 사용해서 지금 고객이 원하는 상품을 추천한다. sesion이라는 sequence를 GRU 레이어의 input으로 두어 바로 다음에 올 확률이 높은 아이템을 추천한다.
구조

- 입력
one-hot encoding 된 아이템으로 이루어진 session
본 모델에서는 embedding을 사용하지 않았을 때 더 높은 성능이 나왔다고 하지만 이 이후에 RNN계열 추천 모델은 임베딩 layer을 많이 사용하기도 한다. - GRU layer
sequencial한 item들이 GRU 레이어를 통과하며 아이템들의 순서, 맥락을 학습한다. - 출력
feed-forward network를 통해 최종으로 고른 아이템에 대한 score를 구한다.
feed-forward network도 선택적으로 사용한다.
Session Parallel mini batches
세션의 길이가 사용자마다, 데이터마다 다르다. 길이가 짧은 세션을 그대로 사용하면 학습이 비효율적으로 일어나게 된다.

짤은 세션끼리 병렬적으로 붙혀서 mini batch를 구성한다.
Sampling on the output
아이템 수가 많아서 모든 후보에 대한 아이템의 확률을 구할 수 없다. 그래서 아이템을 negative sampling 한 subset의 loss만 계산한다. 그러면 상호작용 하지 않은 아이템은 아예 데이터가 없다.

그래서 인기에 기반한 negatrive sampling을 사용한다. 상호작용이 없는 아이템 중에서 인기가 높은 아이템을 negative sampling으로 뽑는다.
결과 및 요약
item-KNN에 대비해서 20% 높은 추천 성능을 보였다. 또한 GRU 레이어의 hidden unit이 많아질수록 더 좋다.
'부스트캠프 AI Tech 3기 > 이론 : U-stage' 카테고리의 다른 글
| [Day37] Context-aware Recommendation 8-2 : FM & FFM (0) | 2022.03.16 |
|---|---|
| [Day37] Context-aware Recommendation 8-1 What is Context-aware Recommendation (0) | 2022.03.16 |
| [Day35] RecSys with DL 7-1 RecSys with GNN (0) | 2022.03.14 |
| [Day33] RecSys with DL 6-2 RecSys with AE (0) | 2022.03.14 |
| [Day33] RecSys with DL 6-1 RecSys with DL/MLP (0) | 2022.03.12 |



