NN은 Vector Space에서 내가 원하는 Query Vector와 가장 유사한 vector를 찾는 알고리즘이다.
NN(Nearest Neighbor)문제는 추천시스템과 많이 관련되어 있지는 않다. Matrix Factorization은 유저와 아이템 사이의 유사도연산이나 아이템 후보끼리 유사도연산을 해야했다. 하지만 추천 모델 서빙 자체는 NN을 찾는 것과 유사하다. 모델학습을 통해서 유저 vector나 아이템 vector과 생성되었고, 추천 모델을 서빙하기 위해서는 vector가 주어졌을 때 그 vector와 가장 인접한 유사한 이웃을 찾는 기법과 일맥상통하다.
Brute Force KNN
정확한 NN을 구하기 위해서는 주어진 vector와 모든 vector들과의 유사도를 다 구해서 가장 유사도가 가까운 K개를 찾아준다.
그렇기 때문에 벡터의 차원과 벡터의 갯수가 많아질수록 선형적으로 비례한 시간이 소요된다. 너무 많은 시간이 걸리기 때문에 현업에서 이 모든 연산을 할 수 없다.

따라서 정확성을 조금 포기하더라도 approximate Neighborhood를 빠르게 찾는 요구가 생긴다.
100%정확도 100ms속도 (X) → 90%정확도 2ms속도 (O)
이 기법이 ANN이다.
시간이 빨라질수록 정확도가 낮아지고, 정확도가 높아질수록 시간이 오래걸리는 approxy와 speed의 trade-off를 적절히 하는 것이 중요하다.
ANN : Approximate Nearest Neighbor
ANNOY
주어진 벡터들을 여러 개의 부분집합으로 나누어 tree 형태의 자료구조로 구성해 tree로 효율적으로 검색하는 기법이다.

vector하나를 점 하나로 표현했다.
- 임의의 두 점을 선택해서 두 점 사이의 hyperplane으로 vector space를 나눈다. 나누어진 각각이 subspace가 된다.
위의 그림의 예시는 2차원이고, 2차원의 hyperplane은 1차원 직선이 된다. - subpace하나는 tree에서 하나의 노드가 된다.
- 이 과정을 반복하면 많은 subspace가 생긴다
- subspace를 binary tree로 바꾼다
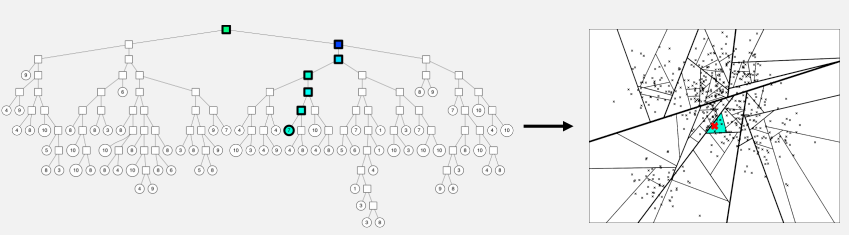
주어진 query vector가 속해 있는 vector space를 $log(n)$시간만에 찾을 수 있다. 해당 space의 vector들과 주어진 vector와의 유사도만을 연산한다. 그 중 가장 가까운 이웃을 찾는다.
문제점
hyperplane이 잘못 나뉘어져서 가장 근접한 점이 다른 space(=node=subset)에 가장 유사한 vector가 있다면 유사도 연산을 계산하는 후보에 속하지도 못한다. random하게 나누기 때문에 이런 상황이 있을 수 있다.
그래서 search대상 space를 늘려서 좀 더 많은 space에 대해서 탐색한다.
- priority queue
트리 내에 가까운 노드도 탐색하게 queue에 추가하여 탐색한다.
물리적으로 가까이 있는 space를 고른다. 그러면 탐색해야 할 space가 많아져서 시간은 좀 더 오래걸리지만, 정확도는 올라가는 trade off가 발생한다. - binary tree를 여러 개 생성
여러 개의 트리를 병렬적으로 탐색하는 일종의 앙상블이다.
1번과 같이 search space가 많아져서 정확도가 향상된다.

Annoy parameter
- search k
NN을 구할 때 탐색하는 node 개수
1번에 대한 parameter
- number of trees
생성하는 binary tree 개수
2번에 대한 parameter
특징
- search index를 생성하는 것이 다른 ANN기법들이 비해서 간단하다.
아이템 갯수가 적고 벡터의 차원이 낮을 때는 적합하다 ->적은 dataset에 대해서 자주 적용 - GPU 사용 불가
- search해야할 이웃의 갯수를 보장
반드시 k개의 이웃을 찾아야하면 k개의 노드를 탐색하면 보장된다. - 파라미터 조정을 통해 accuracy-speed trade-off를 조절할 수 있다.
- 새 데이터를 추가하려면 다시 tree를 만들어야 한다.
HNSW : Hierarchical Navigable Small World graphs
벡터를 그래프로 표현한다.
노드 = vector
유사도가 가까운, 즉 물리적으로 가까이 있는 노드를 edge로 연결한다.
- Small World Graph
전체 벡터 가운데 물리적으로 가까이 있는 점들만 연결한 그래프
유사한 노드들 끼리만 edge를 갖는다. - Navigable
Small World Graph 각각을 연결해주는 Long edge가 있다. 이 long edge로 유사하지 않은(=멀리 있는) 노드들도 탐색할 수 있다. - Hierarchical
naviabla small world graph를 계층적으로 나타냈다.
계층적으로 탐색해서 search speed를 높힌다.

그래프 생성 방법
- layer0에서 모든 노드를 사용해서 navigable small world graph를 만든다.
- random sampling으로 일부 벡터만 살려서 layer1을 만든다
- 또 일부 벡터만 random sampling해서 layer2를 만든다.
가장 끝의 layer에 가장 적은 vector가 남게 된다.
작동 방식
- 가장 끝(숫자가 가장 큰 layer)에서 임의의 노드(빨강)을 선택해서 탐색 시작
- 주어진 query vector(초록)와 유사한 노드로 이동한다
- 더 가까워질 수 없다면 layer을 하나 내려간다
- 2,3번을 반복해서 타겟노드에 도착한다.
- 방문했던 모든 노드들에 대해서 유사도를 구한다.
nmslib, faiss라는 library로 구현해 볼 수 있다.
IVF : Inverted File Index
search space를 줄이는 방법이다.
- k-means와 같은 clustering방법을 통해 전체 space를 n개의 cluster로 나눈다.
- vector의 index를 cluster별로 나누어 list로 저장한다.
- query vector가 포함되어 있는 cluster의 list안의 vector에 대해서 탐색한다.
ANNOY의 문제점과 마찬가지러 아슬아슬하게 다른 cluster에 유사도가 높은 vector가 존재한다면 여러 cluster를 탐색해야한다.
Product Quantization : PQ
기존 vector가 가진 값들을 압축해서 유사도 연산을 빠르게 한다.

- 기존 vector를 n개의 sub-vector로 나눈다.
- 각 sub-vector에 대해서 k-means clustering으로 centroid를 구한다.
- 그 centroid로 sub-vector를 대체한다.

기존 embedding vector의 정확한 값은 사라지지만 최대한 유사하게 유지시킬 수 있다. 그래서 두 벡터의 유사도를 구하는 연산이 거의 요구되지 않는다. 미리 centroid를 구해놓았기 때문에 centroid사이의 유사도를 활용하면 되기 때문이다. $O(1)$의 연산에 수렴한다.
PQ와 IVF는 독립된 기법이어서 PQ의 유사도 연산 속도의 증가 & IVF의 탐색공간 확장을 동시에 사용해서 더 빠르고 효율적으로 수행할 수 있다. (IVF-PQ)
'부스트캠프 AI Tech 3기 > 이론 : U-stage' 카테고리의 다른 글
| [Day33] RecSys with DL 6-2 RecSys with AE (0) | 2022.03.14 |
|---|---|
| [Day33] RecSys with DL 6-1 RecSys with DL/MLP (0) | 2022.03.12 |
| [Day33] Item2Vec and ANN 5-1 Word2Vec & Item2Vec (0) | 2022.03.12 |
| [Day32] Collaborative Filtering 4-3 Bayesian Personalized Ranking (0) | 2022.03.09 |
| [Day32] Collaborative Filtering 4-2 MF & MF for Implicit Feedback (0) | 2022.03.09 |



