prior_question_elapsed_time과 prior_question_had_explanation이라는 열이 잘 이해가 되지 않아서 이 글을 쓰게 되었다.
Data discription
train.csv
row_id: (int64) ID code for the row. 행 마다 순서대로 좌르르 붙혀지는 id
timestamp: (int64) the time in milliseconds between this user interaction and the first event completion from that user. 헷갈리는 부분의 시작이다. 이 discussion 에 따르면 이라고 하는데 그니까 문제를 제출한 클릭한 그 시간에 timestamp가 찍힌다.
user_id: (int32) ID code for the user. 그 문제를 풀고 있는 사용자의 id 사용자 한 명의 기록별로 나열되어 있다.
content_id: (int16) ID code for the user interaction 밑의 content_type_id가 0이면 문제에 대한 question_id를 담고 있는 것이고, content_type_id가 1이면 강의에 대한 lecture_id를 나타낸다. 각각은 question.csv파일과 lectures.csv에서 찾아서 더 깊은 정보와 연관지을 수 있다.
content_type_id: (int8) 0 if the event was a question being posed to the user, 1 if the event was the user watching a lecture. 0이면 문제(question), 1이면 강의(lecture)를 나타낸다.
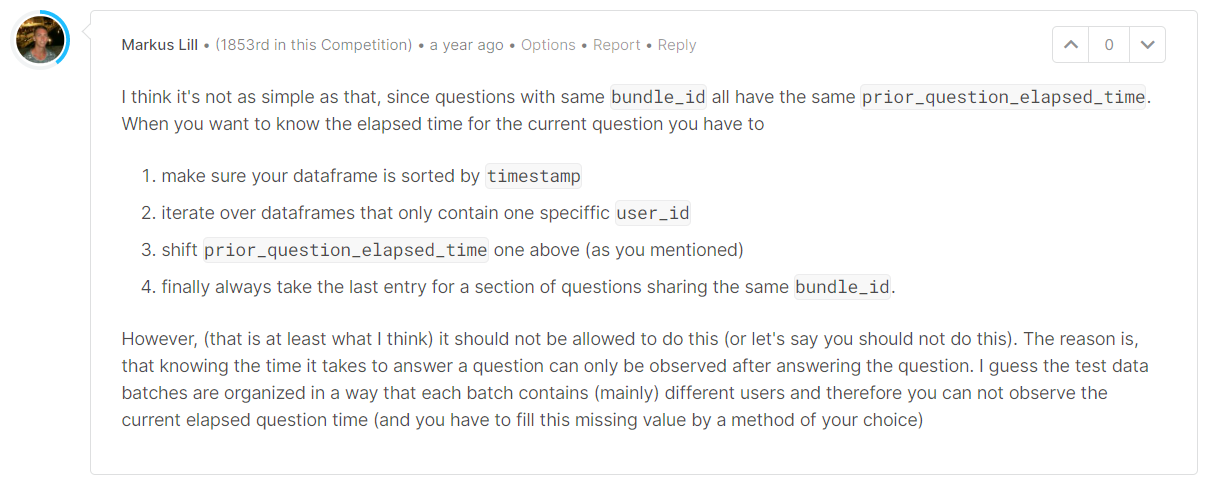
task_container_id: (int16) Id code for the batch of questions or lectures. For example, a user might see three questions in a row before seeing the explanations for any of them. Those three would all share atask_container_id. bundle 이렇게 한 지문에 3개의 문제가 묶여 있는 경우, 그 묶음에 번호를 매긴 것. ex) 149, 150, 151문제의 task_container_id는 모두 같다 묶여져 있지 않은 문제 각 문제가 하나의 문제인 것은 그냥 하나의 아이디를 차지한다. 이 아이디가 같으면 prior_question_elapsed_time가 전체 시간를 문제의 수로 나누기한 것이라서 같다. ex) 149, 150, 151 을 푸는데 150초가 걸렸으면 모두 prior_question_elapsed_time가 150/3=50이다. 밑에서 다시 언급하겠지만 prior이기 때문에 이 50 이라는 값은 다음 행들로 넘어간다고 나는 예상한다.
user_answer: (int8) the user's answer to the question, if any. Read -1 as null, for lectures. A -> 0 B -> 1 C -> 2 D -> 3 문제가 아니라서 답이 생성되지 않는 lecture의 경우(content_type_id가 1일 경우) -> -1
answered_correctly: (int8) if the user responded correctly. Read -1 as null, for lectures. 0 : 틀렸다 1 : 맞다 -1: 강의에 대한 row(content_type_id가 1일 경우)이면 –1이다.
prior_question_elapsed_time: (float32) The average time in milliseconds it took a user to answer each question in the previous question bundle, ignoring any lectures in between. Is null for a user's first question bundle or lecture. Note that the time is the average time a user took to solve each question in the previous bundle. 이 글을 쓰게 된 계기. 엄청나게 헷갈린다 바로 전에 풀었던 문제 묶음(ex 3개가 한 묶음)을 풀었을 때, 한 문제당 걸린 평균시간이다. 위에서 설명했던 것 처럼 묶여져 있기 때문에 평균시간으로 밖에 측정되지 않는다. 내가 이해한 바로는 이렇게 되는 것으로 이해했다.
캐글 관리자님이 이 discussion 에서정리하면 이렇다 9:59:00 문제1 풀기시작 10:00:00 문제1 다 풀음 근데 이건 첫 번째 문제라 prior_question_elapsed_time 이 null임 10:59:30 문제2 풀기 시작 11:00:00 문제2 다풀음 문제 2의 행에는 30초가 아닌 문제1의 시간인 60가 기록됌 (왜 이렇게 기록했어야만 할까...)
이렇게 하나씩 밀린다고 이해했다
prior_question_had_explanation: (bool) Whether or not the user saw an explanation and the correct response(s) after answering the previous question bundle, ignoring any lectures in between. The value is shared across a single question bundle, and is null for a user's first question bundle or lecture. Typically the first several questions a user sees were part of an onboarding diagnostic test where they did not get any feedback. lecture은 무시하고 전 문제를 풀고 난 후에 문제에 대한 설명과 답을 보았는지 이 항목도 사용자의 아주 맨 처음 문제에 대해서는 null이다
어떻게 처리해야 할까
그래서 이것들을 다 위로 하나씩 shift 해야 되는가를 고민했는데
shift 하는 방법과 어차피 예상할 때는 다음 것을 예상하기 때문에 굳이 current 값으로 처리해줄 필요가 없다는 내용(discussion)이 있었다.