다양한 오픈 CTR 데이터에 대해서 GBM 모델이 FM,FFM 계열보다 높은 성능을 보이고 있다.
라이브 서비스시에는 데이터의 특징에 다양한 환경에 따라 바뀌기 쉽게 때문에 데이터의 특성에 관계없이 하이퍼파라미터에 민감하지 않은 robust한 모델을 원한다. 이 때에, FM계열 < 기존의 휴리스틱 모델 < GBM 계열 모델 순으로 성능이 좋았다.
Boosting
앙상블 기법의 일종.
앙상블은 한 가지 모델만 사용시에 생기는 편향에 따른 예측 오차를 줄이기 위해서 여러 모델을 한 번 예측하는데 결합해서 사용하는 기법이다.
Decision tree로 된 weak learner들을 연속적으로 학습하여 결합하는데, 여기에서 weak learner는 정확도와 복잡도가 비교적 낮은 간단한 분류기 이다. 이전 단계의 weak learner가 취약해서 틀리는 부분을 위주로 해당 데이터를 샘플링해서 연속적으로 다음 단계의 weak learner를 학습한다. 이 과정을 반복하며 weak learner가 여러 개 생성되고, 여러 개의 weak learner에 대해서 추론하여 합쳐서 최종 예측값을 구하게 된다.
이런 boosting을 기반한 모델이 XGBoost, LightGBM, AdaBoost,CatBoost 등이 있다.
GBM : Gradient Boosting Machine
gradient descent를 사용해서 loss function이 줄어드는 방향(=negative gradient)을 예측해서 weak learner들을 반복적으로 결합해서 성능을 향상 시키는 Boosting알고리즘.
gradient descent를 사용해서 학습 파라미터를 학습하는 보통의 GD 방법이 아닌, negative gradient로 weak learner를 추가한다는 방식에서 완전히 다르다는 것에 주의해야 한다.

에서 (3번째 줄)$\frac{\partial L(y_i, F(x_{i}))}{\partial F(x_i)}$항을 보면 gradient의 분모가 파라미터가 아니라 learner인 $f(x_i)$가 들어갔다. $f(x_i)$로 loss를 미분하는 gradient를 구한다. gradient에 -를 붙혀 negative하게 만들어 새 예측값$\tilde(y_i)$을 만든다. $\tilde(y_i)$는 m번째 for 문을 돌기 이전까지 만들어진 모델 $F_{m-1}$에 대한 잔차이다.
(4번째 줄) $\tilde(y_i)$를 다시 예측하는 새로운 weak learner $h()$를 학습한다. $a_m$은 $h(x;a_m)$의 파라미터이고 이 파라미터를 업데이트 하는 것이 학습이다. argmin을 구하는 것이 통계적 관점에서 잔차를 줄이눈 것으로 볼 수 있다.
통계학적 관점에서 negative gradient는 실제값-예측값 인 residual이라고 볼 수 있다. 그래서 gradient boosting에서 weak learner가 학습되는 과정은 이전까지의 residual(잔차)를 계산하고, residual을 예측하는 다음 단계의 weak learner를 학습시키는 과정이라고 볼 수 있다.
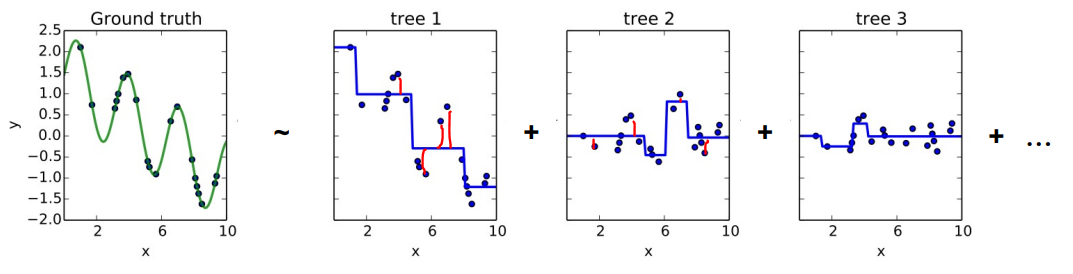
맨 왼쪽의 ground truth가 x와 y의 데이터에 대해 학습한 true function을 보여주고 있다. 예측모델을 학습해서 ground truth와 최대한 비슷하게 만들어야 한다. tree1,2,3는 각각 weak learner이다. tree1을 학습시켜서 residual(빨간색 선만큼의 차이)을 구한다. 이 값(residual)들을 다음 weak learner인 tree2를 학습시키는데 사용한다. 그리고 또 tree2에서의 residual을 구해서 tree를 학습시킨다. 이 과정을 반복하면 tree는 점점 많아지고, residual은 줄어들게 되며 ground truth와 비슷한 function이 학습되게 될 것이다.
회귀문제에서는 위의 빨간 선만큼의 차이를 weak learner의 예측값인 residual로 바로 사용하고, 분류문제에서는 0~1사이로 표현하기 어렵기 때문에 log(odds)값을 사용해서 residual을 계산한다.
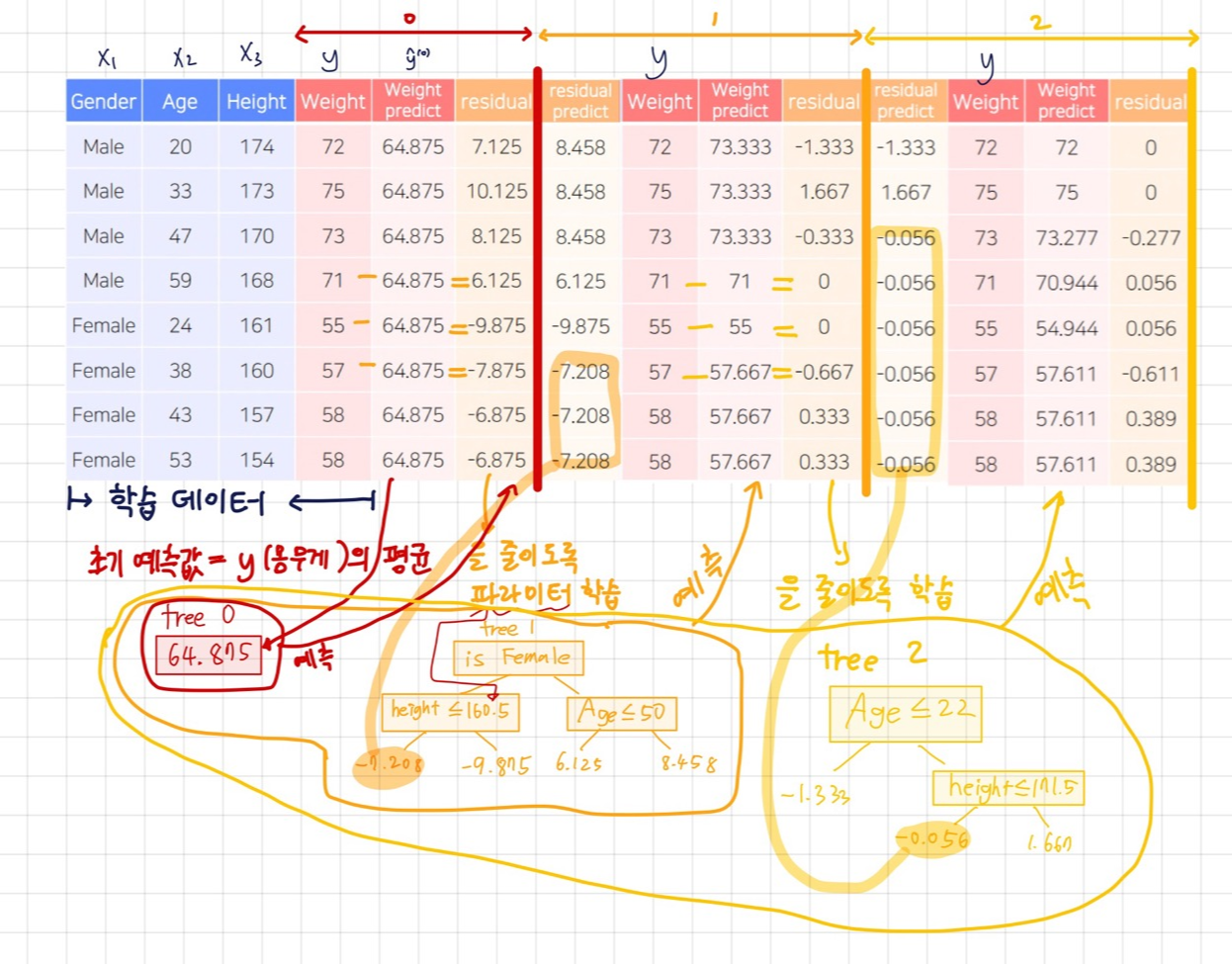
예시를 들어서 residual로 학습되는 과정을 담았다.
Gradient Boosting의 장단점
- 장점
- tree 계열의 앙상블모델(ex. random forest)보다 대체적으로 좋은 성능을 보인다
random forest는 bagging을 활용한 방법인데, 같은 weak learner를 bagging하는 것 보다 boosting하는 것이 낫다고 알려져 있다.
- tree 계열의 앙상블모델(ex. random forest)보다 대체적으로 좋은 성능을 보인다
- 단점
- 순차적으로 weak learner를 학습해서 속도가 느리다.
- 모델이 residual에 맞게 학습하면 overfitting될 수 있다.
대표적인 모델
Gradient Boosting의 단점을 보완하는 모델들이 나오게 된다.
- XG Boost : Extreme gradient boosting
학습을 병렬로 처리하고, 근사 알고리즘을 사용해서 학습 속도를 개선했다. - Light GBM
가볍다. 병렬로 처리하지 않아도 빠르게 Gradient Boosting을 학습할 수 있다. - CatBoost
데이터에 특히 categorical feature가 많을 때, categorical feature에 효과적인 알고리즘을 구현해서, 성능도 높히고, 속도를 개선했고 과적합도 방지한다.
'부스트캠프 AI Tech 3기 > 이론 : U-stage' 카테고리의 다른 글
| [Day38] DeepCTR 9-2 : DIN & BST (0) | 2022.03.17 |
|---|---|
| [Day38] DeepCTR 9-1 : CTR Prediction with DL & Wide&Deep & DeepFM (0) | 2022.03.17 |
| 추천 모델에 따른 데이터 사용 정보 (0) | 2022.03.16 |
| [Day37] Context-aware Recommendation 8-2 : FM & FFM (0) | 2022.03.16 |
| [Day37] Context-aware Recommendation 8-1 What is Context-aware Recommendation (0) | 2022.03.16 |


